> For the complete documentation index, see [llms.txt](https://hswsp.gitbook.io/algorithm/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://hswsp.gitbook.io/algorithm/datastructure/bing-cha-ji.md).
# 并查集
## 定义
并查集主要用于解决一些元素分组的问题。它管理一系列不相交的集合,并支持两种操作: 合并(Union):把两个不相交的集合合并为一个集合。 查询(Find):查询两个元素是否在同一个集合中。
初始化
```cpp
int fa[MAXN];
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
fa[i] = i;
}
```
查询
```cpp
int find(int x)
{
if(fa[x] == x)
return x;
else
return find(fa[x]);
}
```
合并
```cpp
inline void merge(int i, int j)
{
fa[find(i)] = find(j);
}
```
合并查询(Find)(路径压缩)
```cpp
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
```
用此方法合并 j 到 i
```cpp
father[j] = find(father[i]);//并查集合并
```
### 按秩合并
我们应该把简单的树往复杂的树上合并,而不是相反。因为这样合并后,到根节点距离变长的节点个数比较少。 我们用一个数组rank\[]记录每个根节点对应的树的深度(如果不是根节点,其rank相当于以它作为根节点的子树的深度)。一开始,把所有元素的rank(秩)设为1。合并时比较两个根节点,把rank较小者往较大者上合并。路径压缩和按秩合并如果一起使用,时间复杂度接近  ,但是很可能会破坏rank的准确性。
初始化(按秩合并)
```cpp
inline void init(int n)
{
for (int i = 0; i < n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
```
合并(按秩合并)
```cpp
inline void merge(int i, int j)
{
int x = find(i), y = find(j); //先找到两个根节点
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++; //如果深度相同且根节点不同,则新的根节点的深度+1
}
```
最后总结
```cpp
class UF {
// 连通分量个数
int count;
// 存储一棵树
int* fa;
// 记录树的“重量”
int* rank;
public :
UF(int n) {
this.count = n;
fa = new int[n];
size = new int[n];
for (int i = 0; i < n; i++) {
fa[i] = i;
rank[i] = 1;
}
}
void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 小树接到大树下面,较平衡
if (rank[rootP] > rank[rootQ]) {
fa[rootQ] = rootP;
rank[rootP] += rank[rootQ];
} else {
fa[rootP] = rootQ;
rank[rootQ] += rank[rootP];
}
count--;
}
boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
int find(int x) {
while (f[x] != x) {
// 进行路径压缩
f[x] = f[parent[x]];
x = parent[x];
}
return x;
}
}
```
## 例子
### 一、(洛谷P1551)亲戚
题目背景 若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。 题目描述 规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚。如果x,y是亲戚,那么x的亲戚都是y的亲戚,y的亲戚也都是x的亲戚。 输入格式 第一行:三个整数n,m,p,(n<=5000,m<=5000,p<=5000),分别表示有n个人,m个亲戚关系,询问p对亲戚关系。 以下m行:每行两个数Mi,Mj,1<=Mi,Mj<=N,表示Mi和Mj具有亲戚关系。 接下来p行:每行两个数Pi,Pj,询问Pi和Pj是否具有亲戚关系。 输出格式 P行,每行一个’Yes’或’No’。表示第i个询问的答案为“具有”或“不具有”亲戚关系。
```cpp
#include
#define MAXN 5005
int fa[MAXN], rank[MAXN];
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
inline void merge(int i, int j)
{
int x = find(i), y = find(j);
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++;
}
int main()
{
int n, m, p, x, y;
scanf("%d%d%d", &n, &m, &p);
init(n);
for (int i = 0; i < m; ++i)
{
scanf("%d%d", &x, &y);
merge(x, y);
}
for (int i = 0; i < p; ++i)
{
scanf("%d%d", &x, &y);
printf("%s\n", find(x) == find(y) ? "Yes" : "No");
}
return 0;
}
```
### 二、(NOIP提高组2017年D2T1) 洛谷P3958 奶酪
题目描述
现有一块大奶酪,它的高度为,它的长度和宽度我们可以认为是无限大的,奶酪中间有许多半径相同的球形空洞。我们可以在这块奶酪中建立空间坐标系,在坐标系中, 奶酪的下表面为 ,奶酪的上表面为 。 现在,奶酪的下表面有一只小老鼠 Jerry,它知道奶酪中所有空洞的球心所在的坐标。如果两个空洞相切或是相交,则 Jerry 可以从其中一个空洞跑到另一个空洞,特别地,如果一个空洞与下表面相切或是相交,Jerry 则可以从奶酪下表面跑进空洞;如果一个空洞与上表面相切或是相交,Jerry 则可以从空洞跑到奶酪上表面。 位于奶酪下表面的 Jerry 想知道,在 不破坏奶酪 的情况下,能否利用已有的空洞跑到奶酪的上表面去? 空间内两点  、 的距离公式如下: 
输入格式 每个输入文件包含多组数据。接下来的第一行,包含一个正整数  ,代表该输入文件中所含的数据组数。 接下来是 组数据,每组数据的格式如下: 第一行包含三个正整数 和  ,两个数之间以一个空格分开,分别代表奶酪中空 洞的数量,奶酪的高度和空洞的半径。 接下来的 行,每行包含三个整数 ,两个数之间以一个空格分开,表示空 洞球心坐标为  。
输出格式 行,分别对应组数据的答案,如果在第  组数据中,Jerry 能从下表面跑到上表面,则输出Yes,如果不能,则输出No(均不包含引号)。
我们把所有空洞划分为若干个集合,一旦两个空洞相交或相切,就把它们放到同一个集合中。
我们还可以划出2个特殊元素,分别表示底部和顶部,如果一个空洞与底部接触,则把它与表示底部的元素放在同一个集合中,顶部同理。最后,只需要看顶部和底部是不是在同一个集合中即可。这完全可以通过并查集实现。来看代码:
```cpp
#include
#include
#define MAXN 1005
typedef long long ll;
int fa[MAXN], rank[MAXN];
ll X[MAXN], Y[MAXN], Z[MAXN];
inline bool next_to(ll x1, ll y1, ll z1, ll x2, ll y2, ll z2, ll r)
{
return (x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2) + (z1 - z2) * (z1 - z2) <= 4 * r * r;
//判断两个空洞是否相交或相切
}
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
inline void merge(int i, int j)
{
int x = find(i), y = find(j);
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++;
}
int main()
{
int T, n, h;
ll r;
scanf("%d", &T);
for (int I = 0; I < T; ++I)
{
memset(X, 0, sizeof(X));
memset(Y, 0, sizeof(Y));
memset(Z, 0, sizeof(Z));
scanf("%d%d%lld", &n, &h, &r);
init(n);
fa[1001] = 1001; //用1001代表底部
fa[1002] = 1002; //用1002代表顶部
for (int i = 1; i <= n; ++i)
scanf("%lld%lld%lld", X + i, Y + i, Z + i);
for (int i = 1; i <= n; ++i)
{
if (Z[i] <= r)
merge(i, 1001); //与底部接触的空洞与底部合并
if (Z[i] + r >= h)
merge(i, 1002); //与顶部接触的空洞与顶部合并
}
for (int i = 1; i <= n; ++i)
{
for (int j = i + 1; j <= n; ++j)
{
if (next_to(X[i], Y[i], Z[i], X[j], Y[j], Z[j], r))
merge(i, j); //遍历所有空洞,合并相交或相切的球
}
}
printf("%s\n", find(1001) == find(1002) ? "Yes" : "No");
}
return 0;
}
```
### 三、DFS 的替代方案
很多使用 DFS 深度优先算法解决的问题,也可以用 Union-Find 算法解决。
比如第 130 题,被围绕的区域:给你一个 M×N 的二维矩阵,其中包含字符`X`和`O`,让你找到矩阵中**完全**被`X`围住的`O`,并且把它们替换成`X`。 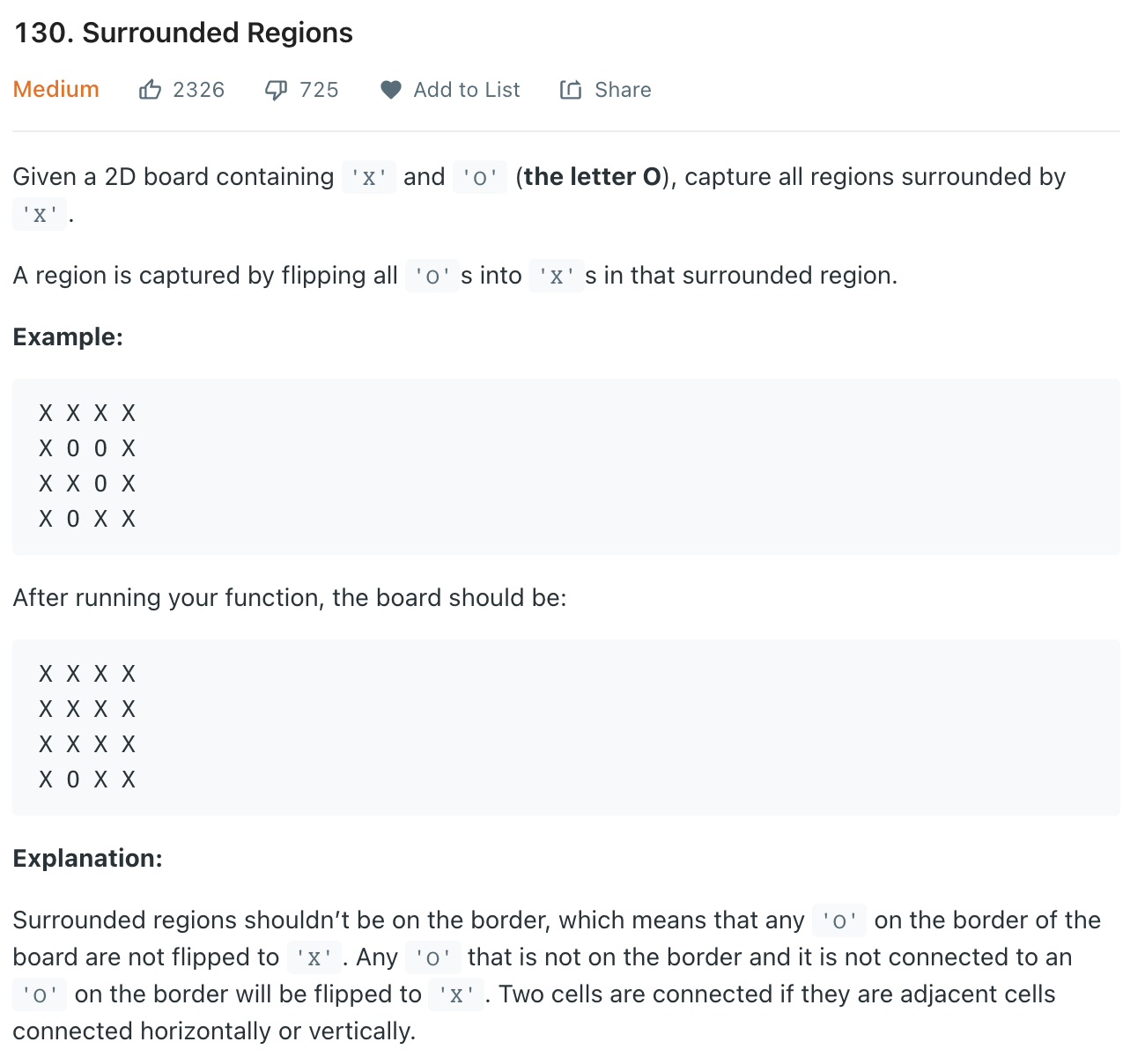

```cpp
void solve(char[][] board);
```
注意哦,必须是完全被围的`O`才能被换成`X`,也就是说边角上的`O`一定不会被围,进一步,与边角上的`O`相连的`O`也不会被`X`围四面,也不会被替换:

解决这个问题的传统方法也不困难,先用 for 循环遍历棋盘的**四边**,用 DFS 算法把那些与边界相连的`O`换成一个特殊字符,比如`#`;然后再遍历整个棋盘,把剩下的`O`换成`X`,把`#`恢复成`O`。这样就能完成题目的要求,时间复杂度 O(MN)。
```cpp
class Solution {
public:
void solve(vector>& board) {
if (board.empty() || board[0].empty()) return;
int m = board.size(), n = board[0].size();
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (i == 0 || i == m - 1 || j == 0 || j == n - 1) {
if (board[i][j] == 'O') dfs(board, i , j);
}
}
}
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (board[i][j] == 'O') board[i][j] = 'X';
if (board[i][j] == '$') board[i][j] = 'O';
}
}
}
void dfs(vector> &board, int x, int y) {
int m = board.size(), n = board[0].size();
vector> dir{{0,-1},{-1,0},{0,1},{1,0}};
board[x][y] = '$';
for (int i = 0; i < dir.size(); ++i) {
int dx = x + dir[i][0], dy = y + dir[i][1];
if (dx >= 0 && dx < m && dy > 0 && dy < n && board[dx][dy] == 'O') {
dfs(board, dx, dy);
}
}
}
};
```
这个问题也可以用 Union-Find 算法解决,虽然实现复杂一些,甚至效率也略低,但这是使用 Union-Find 算法的通用思想,值得一学。
**你可以把那些不需要被替换的`O`看成一个拥有独门绝技的门派,它们有一个共同祖师爷叫`dummy`,这些`O`和`dummy`互相连通,而那些需要被替换的`O`与`dummy`不连通**。
这就是 Union-Find 的核心思路,明白这个图,就很容易看懂代码了:

首先要解决的是,根据我们的实现,Union-Find 底层用的是一维数组,构造函数需要传入这个数组的大小,而题目给的是一个二维棋盘。
这个很简单,二维坐标`(x,y)`可以转换成`x * n + y`这个数(`m`是棋盘的行数,`n`是棋盘的列数)。敲黑板,**这是将二维坐标映射到一维的常用技巧**。
其次,我们之前描述的「祖师爷」是虚构的,需要给他老人家留个位置。索引`[0.. m*n-1]`都是棋盘内坐标的一维映射,那就让这个虚拟的`dummy`节点占据索引`m*n`好了。
```cpp
void solve(char[][] board) {
if (board.length == 0) return;
int m = board.length;
int n = board[0].length;
// 给 dummy 留一个额外位置
UF uf = new UF(m * n + 1);
int dummy = m * n;
// 将首列和末列的 O 与 dummy 连通
for (int i = 0; i < m; i++) {
if (board[i][0] == 'O')
uf.union(i * n, dummy);
if (board[i][n - 1] == 'O')
uf.union(i * n + n - 1, dummy);
}
// 将首行和末行的 O 与 dummy 连通
for (int j = 0; j < n; j++) {
if (board[0][j] == 'O')
uf.union(j, dummy);
if (board[m - 1][j] == 'O')
uf.union(n * (m - 1) + j, dummy);
}
// 方向数组 d 是上下左右搜索的常用手法
int[][] d = new int[][]{{1,0}, {0,1}, {0,-1}, {-1,0}};
for (int i = 1; i < m - 1; i++)
for (int j = 1; j < n - 1; j++)
if (board[i][j] == 'O')
// 将此 O 与上下左右的 O 连通
for (int k = 0; k < 4; k++) {
int x = i + d[k][0];
int y = j + d[k][1];
if (board[x][y] == 'O')
uf.union(x * n + y, i * n + j);
}
// 所有不和 dummy 连通的 O,都要被替换
for (int i = 1; i < m - 1; i++)
for (int j = 1; j < n - 1; j++)
if (!uf.connected(dummy, i * n + j))
board[i][j] = 'X';
}
```
这段代码很长,其实就是刚才的思路实现,只有和边界`O`相连的`O`才具有和`dummy`的连通性,他们不会被替换。
说实话,Union-Find 算法解决这个简单的问题有点杀鸡用牛刀,它可以解决更复杂,更具有技巧性的问题,**主要思路是适时增加虚拟节点,想办法让元素「分门别类」,建立动态连通关系**。
### 四、判定合法算式
这个问题用 Union-Find 算法就显得十分优美了。题目是这样:
给你一个数组`equations`,装着若干字符串表示的算式。每个算式`equations[i]`长度都是 4,而且只有这两种情况:`a==b`或者`a!=b`,其中`a,b`可以是任意小写字母。你写一个算法,如果`equations`中所有算式都不会互相冲突,返回 true,否则返回 false。
比如说,输入`["a==b","b!=c","c==a"]`,算法返回 false,因为这三个算式不可能同时正确。
再比如,输入`["c==c","b==d","x!=z"]`,算法返回 true,因为这三个算式并不会造成逻辑冲突。
我们前文说过,动态连通性其实就是一种等价关系,具有「自反性」「传递性」和「对称性」,其实`==`关系也是一种等价关系,具有这些性质。所以这个问题用 Union-Find 算法就很自然。
核心思想是,**将`equations`中的算式根据`==`和`!=`分成两部分,先处理`==`算式,使得他们通过相等关系各自勾结成门派;然后处理`!=`算式,检查不等关系是否破坏了相等关系的连通性**。
```cpp
boolean equationsPossible(String[] equations) {
// 26 个英文字母
UF uf = new UF(26);
// 先让相等的字母形成连通分量
for (String eq : equations) {
if (eq.charAt(1) == '=') {
char x = eq.charAt(0);
char y = eq.charAt(3);
uf.union(x - 'a', y - 'a');
}
}
// 检查不等关系是否打破相等关系的连通性
for (String eq : equations) {
if (eq.charAt(1) == '!') {
char x = eq.charAt(0);
char y = eq.charAt(3);
// 如果相等关系成立,就是逻辑冲突
if (uf.connected(x - 'a', y - 'a'))
return false;
}
}
return true;
}
```
至此,这道判断算式合法性的问题就解决了,借助 Union-Find 算法,是不是很简单呢?
## 简单总结
**使用 Union-Find 算法,主要是如何把原问题转化成图的动态连通性问题**。对于算式合法性问题,可以直接利用等价关系,对于棋盘包围问题,则是利用一个虚拟节点,营造出动态连通特性。
另外,将二维数组映射到一维数组,利用方向数组`d`来简化代码量,都是在写算法时常用的一些小技巧,如果没见过可以注意一下。
很多更复杂的 DFS 算法问题,都可以利用 Union-Find 算法更漂亮的解决。LeetCode 上 Union-Find 相关的问题也就二十多道,有兴趣的读者可以去做一做。
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://hswsp.gitbook.io/algorithm/datastructure/bing-cha-ji.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.
,但是很可能会破坏rank的准确性。
初始化(按秩合并)
```cpp
inline void init(int n)
{
for (int i = 0; i < n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
```
合并(按秩合并)
```cpp
inline void merge(int i, int j)
{
int x = find(i), y = find(j); //先找到两个根节点
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++; //如果深度相同且根节点不同,则新的根节点的深度+1
}
```
最后总结
```cpp
class UF {
// 连通分量个数
int count;
// 存储一棵树
int* fa;
// 记录树的“重量”
int* rank;
public :
UF(int n) {
this.count = n;
fa = new int[n];
size = new int[n];
for (int i = 0; i < n; i++) {
fa[i] = i;
rank[i] = 1;
}
}
void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 小树接到大树下面,较平衡
if (rank[rootP] > rank[rootQ]) {
fa[rootQ] = rootP;
rank[rootP] += rank[rootQ];
} else {
fa[rootP] = rootQ;
rank[rootQ] += rank[rootP];
}
count--;
}
boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
int find(int x) {
while (f[x] != x) {
// 进行路径压缩
f[x] = f[parent[x]];
x = parent[x];
}
return x;
}
}
```
## 例子
### 一、(洛谷P1551)亲戚
题目背景 若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。 题目描述 规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚。如果x,y是亲戚,那么x的亲戚都是y的亲戚,y的亲戚也都是x的亲戚。 输入格式 第一行:三个整数n,m,p,(n<=5000,m<=5000,p<=5000),分别表示有n个人,m个亲戚关系,询问p对亲戚关系。 以下m行:每行两个数Mi,Mj,1<=Mi,Mj<=N,表示Mi和Mj具有亲戚关系。 接下来p行:每行两个数Pi,Pj,询问Pi和Pj是否具有亲戚关系。 输出格式 P行,每行一个’Yes’或’No’。表示第i个询问的答案为“具有”或“不具有”亲戚关系。
```cpp
#include
#define MAXN 5005
int fa[MAXN], rank[MAXN];
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
inline void merge(int i, int j)
{
int x = find(i), y = find(j);
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++;
}
int main()
{
int n, m, p, x, y;
scanf("%d%d%d", &n, &m, &p);
init(n);
for (int i = 0; i < m; ++i)
{
scanf("%d%d", &x, &y);
merge(x, y);
}
for (int i = 0; i < p; ++i)
{
scanf("%d%d", &x, &y);
printf("%s\n", find(x) == find(y) ? "Yes" : "No");
}
return 0;
}
```
### 二、(NOIP提高组2017年D2T1) 洛谷P3958 奶酪
题目描述
现有一块大奶酪,它的高度为,它的长度和宽度我们可以认为是无限大的,奶酪中间有许多半径相同的球形空洞。我们可以在这块奶酪中建立空间坐标系,在坐标系中, 奶酪的下表面为 ,奶酪的上表面为 。 现在,奶酪的下表面有一只小老鼠 Jerry,它知道奶酪中所有空洞的球心所在的坐标。如果两个空洞相切或是相交,则 Jerry 可以从其中一个空洞跑到另一个空洞,特别地,如果一个空洞与下表面相切或是相交,Jerry 则可以从奶酪下表面跑进空洞;如果一个空洞与上表面相切或是相交,Jerry 则可以从空洞跑到奶酪上表面。 位于奶酪下表面的 Jerry 想知道,在 不破坏奶酪 的情况下,能否利用已有的空洞跑到奶酪的上表面去? 空间内两点  、 的距离公式如下: 
输入格式 每个输入文件包含多组数据。接下来的第一行,包含一个正整数  ,代表该输入文件中所含的数据组数。 接下来是 组数据,每组数据的格式如下: 第一行包含三个正整数 和  ,两个数之间以一个空格分开,分别代表奶酪中空 洞的数量,奶酪的高度和空洞的半径。 接下来的 行,每行包含三个整数 ,两个数之间以一个空格分开,表示空 洞球心坐标为  。
输出格式 行,分别对应组数据的答案,如果在第  组数据中,Jerry 能从下表面跑到上表面,则输出Yes,如果不能,则输出No(均不包含引号)。
我们把所有空洞划分为若干个集合,一旦两个空洞相交或相切,就把它们放到同一个集合中。
我们还可以划出2个特殊元素,分别表示底部和顶部,如果一个空洞与底部接触,则把它与表示底部的元素放在同一个集合中,顶部同理。最后,只需要看顶部和底部是不是在同一个集合中即可。这完全可以通过并查集实现。来看代码:
```cpp
#include
#include
#define MAXN 1005
typedef long long ll;
int fa[MAXN], rank[MAXN];
ll X[MAXN], Y[MAXN], Z[MAXN];
inline bool next_to(ll x1, ll y1, ll z1, ll x2, ll y2, ll z2, ll r)
{
return (x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2) + (z1 - z2) * (z1 - z2) <= 4 * r * r;
//判断两个空洞是否相交或相切
}
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
inline void merge(int i, int j)
{
int x = find(i), y = find(j);
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++;
}
int main()
{
int T, n, h;
ll r;
scanf("%d", &T);
for (int I = 0; I < T; ++I)
{
memset(X, 0, sizeof(X));
memset(Y, 0, sizeof(Y));
memset(Z, 0, sizeof(Z));
scanf("%d%d%lld", &n, &h, &r);
init(n);
fa[1001] = 1001; //用1001代表底部
fa[1002] = 1002; //用1002代表顶部
for (int i = 1; i <= n; ++i)
scanf("%lld%lld%lld", X + i, Y + i, Z + i);
for (int i = 1; i <= n; ++i)
{
if (Z[i] <= r)
merge(i, 1001); //与底部接触的空洞与底部合并
if (Z[i] + r >= h)
merge(i, 1002); //与顶部接触的空洞与顶部合并
}
for (int i = 1; i <= n; ++i)
{
for (int j = i + 1; j <= n; ++j)
{
if (next_to(X[i], Y[i], Z[i], X[j], Y[j], Z[j], r))
merge(i, j); //遍历所有空洞,合并相交或相切的球
}
}
printf("%s\n", find(1001) == find(1002) ? "Yes" : "No");
}
return 0;
}
```
### 三、DFS 的替代方案
很多使用 DFS 深度优先算法解决的问题,也可以用 Union-Find 算法解决。
比如第 130 题,被围绕的区域:给你一个 M×N 的二维矩阵,其中包含字符`X`和`O`,让你找到矩阵中**完全**被`X`围住的`O`,并且把它们替换成`X`。 

```cpp
void solve(char[][] board);
```
注意哦,必须是完全被围的`O`才能被换成`X`,也就是说边角上的`O`一定不会被围,进一步,与边角上的`O`相连的`O`也不会被`X`围四面,也不会被替换:

解决这个问题的传统方法也不困难,先用 for 循环遍历棋盘的**四边**,用 DFS 算法把那些与边界相连的`O`换成一个特殊字符,比如`#`;然后再遍历整个棋盘,把剩下的`O`换成`X`,把`#`恢复成`O`。这样就能完成题目的要求,时间复杂度 O(MN)。
```cpp
class Solution {
public:
void solve(vector>& board) {
if (board.empty() || board[0].empty()) return;
int m = board.size(), n = board[0].size();
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (i == 0 || i == m - 1 || j == 0 || j == n - 1) {
if (board[i][j] == 'O') dfs(board, i , j);
}
}
}
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (board[i][j] == 'O') board[i][j] = 'X';
if (board[i][j] == '$') board[i][j] = 'O';
}
}
}
void dfs(vector> &board, int x, int y) {
int m = board.size(), n = board[0].size();
vector> dir{{0,-1},{-1,0},{0,1},{1,0}};
board[x][y] = '$';
for (int i = 0; i < dir.size(); ++i) {
int dx = x + dir[i][0], dy = y + dir[i][1];
if (dx >= 0 && dx < m && dy > 0 && dy < n && board[dx][dy] == 'O') {
dfs(board, dx, dy);
}
}
}
};
```
这个问题也可以用 Union-Find 算法解决,虽然实现复杂一些,甚至效率也略低,但这是使用 Union-Find 算法的通用思想,值得一学。
**你可以把那些不需要被替换的`O`看成一个拥有独门绝技的门派,它们有一个共同祖师爷叫`dummy`,这些`O`和`dummy`互相连通,而那些需要被替换的`O`与`dummy`不连通**。
这就是 Union-Find 的核心思路,明白这个图,就很容易看懂代码了:

首先要解决的是,根据我们的实现,Union-Find 底层用的是一维数组,构造函数需要传入这个数组的大小,而题目给的是一个二维棋盘。
这个很简单,二维坐标`(x,y)`可以转换成`x * n + y`这个数(`m`是棋盘的行数,`n`是棋盘的列数)。敲黑板,**这是将二维坐标映射到一维的常用技巧**。
其次,我们之前描述的「祖师爷」是虚构的,需要给他老人家留个位置。索引`[0.. m*n-1]`都是棋盘内坐标的一维映射,那就让这个虚拟的`dummy`节点占据索引`m*n`好了。
```cpp
void solve(char[][] board) {
if (board.length == 0) return;
int m = board.length;
int n = board[0].length;
// 给 dummy 留一个额外位置
UF uf = new UF(m * n + 1);
int dummy = m * n;
// 将首列和末列的 O 与 dummy 连通
for (int i = 0; i < m; i++) {
if (board[i][0] == 'O')
uf.union(i * n, dummy);
if (board[i][n - 1] == 'O')
uf.union(i * n + n - 1, dummy);
}
// 将首行和末行的 O 与 dummy 连通
for (int j = 0; j < n; j++) {
if (board[0][j] == 'O')
uf.union(j, dummy);
if (board[m - 1][j] == 'O')
uf.union(n * (m - 1) + j, dummy);
}
// 方向数组 d 是上下左右搜索的常用手法
int[][] d = new int[][]{{1,0}, {0,1}, {0,-1}, {-1,0}};
for (int i = 1; i < m - 1; i++)
for (int j = 1; j < n - 1; j++)
if (board[i][j] == 'O')
// 将此 O 与上下左右的 O 连通
for (int k = 0; k < 4; k++) {
int x = i + d[k][0];
int y = j + d[k][1];
if (board[x][y] == 'O')
uf.union(x * n + y, i * n + j);
}
// 所有不和 dummy 连通的 O,都要被替换
for (int i = 1; i < m - 1; i++)
for (int j = 1; j < n - 1; j++)
if (!uf.connected(dummy, i * n + j))
board[i][j] = 'X';
}
```
这段代码很长,其实就是刚才的思路实现,只有和边界`O`相连的`O`才具有和`dummy`的连通性,他们不会被替换。
说实话,Union-Find 算法解决这个简单的问题有点杀鸡用牛刀,它可以解决更复杂,更具有技巧性的问题,**主要思路是适时增加虚拟节点,想办法让元素「分门别类」,建立动态连通关系**。
### 四、判定合法算式
这个问题用 Union-Find 算法就显得十分优美了。题目是这样:
给你一个数组`equations`,装着若干字符串表示的算式。每个算式`equations[i]`长度都是 4,而且只有这两种情况:`a==b`或者`a!=b`,其中`a,b`可以是任意小写字母。你写一个算法,如果`equations`中所有算式都不会互相冲突,返回 true,否则返回 false。
比如说,输入`["a==b","b!=c","c==a"]`,算法返回 false,因为这三个算式不可能同时正确。
再比如,输入`["c==c","b==d","x!=z"]`,算法返回 true,因为这三个算式并不会造成逻辑冲突。
我们前文说过,动态连通性其实就是一种等价关系,具有「自反性」「传递性」和「对称性」,其实`==`关系也是一种等价关系,具有这些性质。所以这个问题用 Union-Find 算法就很自然。
核心思想是,**将`equations`中的算式根据`==`和`!=`分成两部分,先处理`==`算式,使得他们通过相等关系各自勾结成门派;然后处理`!=`算式,检查不等关系是否破坏了相等关系的连通性**。
```cpp
boolean equationsPossible(String[] equations) {
// 26 个英文字母
UF uf = new UF(26);
// 先让相等的字母形成连通分量
for (String eq : equations) {
if (eq.charAt(1) == '=') {
char x = eq.charAt(0);
char y = eq.charAt(3);
uf.union(x - 'a', y - 'a');
}
}
// 检查不等关系是否打破相等关系的连通性
for (String eq : equations) {
if (eq.charAt(1) == '!') {
char x = eq.charAt(0);
char y = eq.charAt(3);
// 如果相等关系成立,就是逻辑冲突
if (uf.connected(x - 'a', y - 'a'))
return false;
}
}
return true;
}
```
至此,这道判断算式合法性的问题就解决了,借助 Union-Find 算法,是不是很简单呢?
## 简单总结
**使用 Union-Find 算法,主要是如何把原问题转化成图的动态连通性问题**。对于算式合法性问题,可以直接利用等价关系,对于棋盘包围问题,则是利用一个虚拟节点,营造出动态连通特性。
另外,将二维数组映射到一维数组,利用方向数组`d`来简化代码量,都是在写算法时常用的一些小技巧,如果没见过可以注意一下。
很多更复杂的 DFS 算法问题,都可以利用 Union-Find 算法更漂亮的解决。LeetCode 上 Union-Find 相关的问题也就二十多道,有兴趣的读者可以去做一做。
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://hswsp.gitbook.io/algorithm/datastructure/bing-cha-ji.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.